- What is a crawler?
- How does crawler work?
- How does the crawler see pages?
- Mobile and desktop rendering
- HTML and JavaScript rendering
- What influences the crawler’s behavior?
- Internal links and backlinks
- Click depth
- Sitemap
- Indexing instructions
- Are all pages available for crawling?
- When will my website appear in search?
- Duplicate content issues
- URL structure issues
- Conclusion
First, Google crawls the web to find new pages. Then, Google indexes these pages to understand what they are about and ranks them according to the retrieved data. Crawling and indexing are two different processes, still, they are both performed by a crawler.
In our new guide, we have collected everything an SEO specialist needs to know about crawlers. Read to see what a crawler is, how it works, and how you can make its interaction with your website more successful.
What is a crawler?
Crawler (also searchbot, spider) is a piece of software Google and other search engines use to scan the Web. Simply put, it "crawls" the web from page to page, looking for new or updated content Google doesn't have in its databases yet.
Any search engine has its own set of crawlers. As for Google, there are more than 15 different types of crawlers, and the main Google crawler is called Googlebot. Googlebot performs both crawling and indexing, that’s why we’ll take a closer look at how it works.
How does crawler work?
There’s no central registry of URLs, which is updated whenever a new page is created. This means that Google isn't "alerted" about them automatically, but has to find them on the web. Googlebot constantly wanders through the Internet and searches for new pages, adding them to Google’s database of existing pages.
Once Googlebot discovers a new page, it renders (visualizes) the page in a browser, loading all the HTML, third-party code, JavaScript, and CSS. This information is stored in the search engine’s database and then used to index and rank the page. If a page has been indexed, it is added to Google Index — one more super-huge Google database.

How does the crawler see pages?
The crawler renders a page in the latest version of Chromium browser. In the perfect scenario, the crawler “sees” a page the way you designed and assembled it. In the realistic scenario, things could turn out more complicated.
Mobile and desktop rendering
Googlebot can “see” your page with two subtypes of crawlers: Googlebot Desktop and Googlebot Smartphone. This division is needed to index pages for both desktop and mobile SERPs.
Some years ago, Google used a desktop crawler to visit and render most of the pages. But things have changed with the mobile-first concept introduction. Google thought that the world became mobile-friendly enough, and started using Googlebot Smartphone to crawl, index, and rank the mobile version of websites for both mobile and desktop SERPs.
Still, implementing mobile-first indexing turned out harder than it was supposed to be. The Internet is huge, and most websites appeared to be poorly optimized for mobile devices. This made Google use the mobile-first concept for crawling and indexing new websites and those old ones that became fully optimized for mobile. If a website is not mobile-friendly, it is firsthand crawled and rendered by Googlebot Desktop.
Even if your website has been converted to mobile-first indexing, you will still have some of your pages crawled by Googlebot Desktop, as Google wants to check how your website performs on desktop. Google doesn’t directly say it will index your desktop version if it differs much from the mobile one. Still, it’s logical to assume this, as Google’s primary goal is to provide users with the most useful information. And Google hardly wants to lose this information by blindly following the mobile-first concept.
Note: In any case, your website will be visited by both Googlebot Mobile and Googlebot Desktop. So it’s important to take care of both versions of your website, and think of using a responsive layout if you haven’t done this yet.
How to know if Google crawls and indexes your website with mobile-first concept? You’ll receive a special notification in Google Search Console.
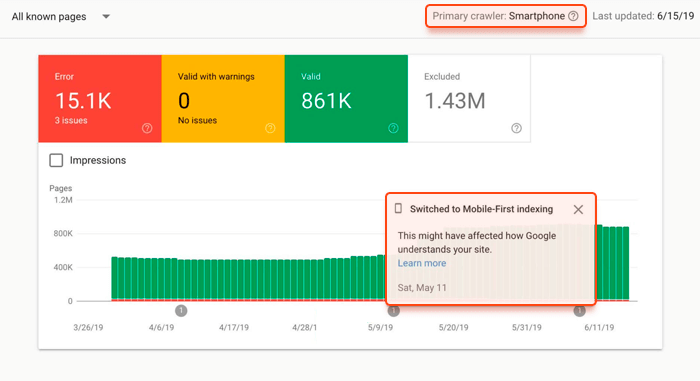
HTML and JavaScript rendering
Googlebot may have some troubles with processing and rendering the bulky code. If your page’s code is messy, the crawler may not manage to render it properly and consider your page empty.
As for JavaScript rendering, you should remember that JavaScript is a quickly evolving language, and Googlebot may sometimes fail to support the latest versions. Make sure your JS is compatible with Googlebot, or your page may be rendered incorrectly.
Mind your JS loading time. If a script needs more than 5 seconds to load, Googlebot will not render and index the content generated by that script.
Note: If your website is full of heavy JS elements, and you cannot do without them, Google recommends server-side rendering. This will make your website load faster and prevent JavaScript bugs.
To see which resources on your page cause rendering issues (and actually see if you have any issues at all), login to your Google Search Console account, go to URL Inspection, enter the URL you want to check, click the Test Live URL button, and click View Tested Page.

Then go to the More Info section and click on the Page Resources and JavaScript console messages folders to see the list of resources Googlebot failed to render.

Now you can show the list of problems to webmasters and ask them to investigate and fix the errors.
What influences the crawler’s behavior?
Googlebot’s behavior is not chaotic — it is determined by sophisticated algorithms, which help the crawler navigate through the web and set the rules of information processing.
Nevertheless, the algorithms’ behavior is not something that you can just do nothing about and hope for the best. Let’s take a closer look at what influences the crawler’s behavior, and how you can optimize your pages’ crawling.
Internal links and backlinks
If Google already knows your website, Googlebot will check your main pages for updates from time to time. That’s why it’s crucial to place the links to new pages on the authoritative pages of your website. Ideally, on the homepage.
You can enrich your homepage with a block that would feature the latest news or blog posts, even if you have separate pages for news and a blog. This would let Googlebot find your new pages much quicker. This recommendation may seem quite obvious, still, many website owners keep neglecting it, which results in poor indexing and low positions.
In terms of crawling, backlinks work the same. So if you add a new page, don’t forget about external promotion. You can try guest posting, launch an ad campaign, or try any other means you prefer to make Googlebot see the URL of your new page.
Note: Links should be dofollow to let Googlebot follow them. Although Google has recently stated that nofollow links could also be used as hints for crawling and indexing, we’d still recommend using dofollow. Just to make sure crawlers do see the page.
Click depth
Click depth shows how far a page is from the homepage. Ideally, any page of a website should be reached within 3 clicks. Bigger click depth slows crawling down, and hardly benefits user experience.
You can use WebSite Auditor to check if your website has any issues related to click depth. Launch the tool, and go to Site Structure > Pages, and pay attention to the Click depth column.

If you see that some important pages are too far from the homepage, reconsider the arrangement of your website’s structure. A good structure should be simple and scalable, so you could add as many new pages as you need without negatively affecting the simplicity.
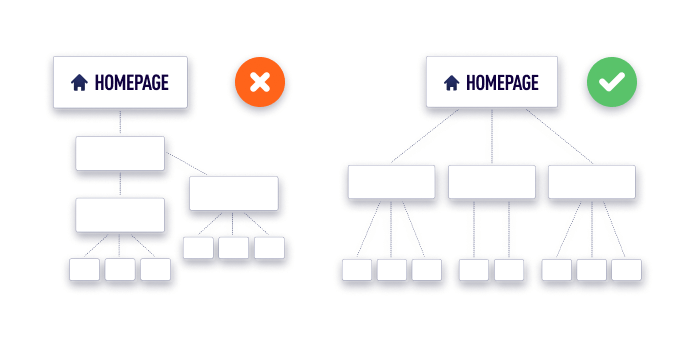
Sitemap
A sitemap is a document that contains the full list of pages you want to be in Google. You can submit a sitemap of your website to Google via Google Search Console (Index > Sitemaps) to let Googlebot know what pages to visit and crawl. A sitemap also tells Google if there are any updates on your pages.
Note: Sitemap does not guarantee that Googlebot will use it when crawling your website. The crawler can ignore your sitemap and keep crawling the website the way it decides. Still, nobody has been fined for having a sitemap, and in most cases, it proves to be useful. Some CMSs even automatically generate a sitemap, update it, and send it to Google to make your SEO process faster and easier. Consider submitting a sitemap if your website is new or big (has more than 500 URLs).
You can assemble a sitemap with WebSite Auditor. Go to Preferences > XML Sitemap Settings > Sitemap Generation, and set up the options you need. Name your sitemap (Sitemap File Name), and download it to your computer to further submit it to Google or publish it to your website (Sitemap Publishing).

Indexing instructions
When crawling and indexing your pages, Google follows certain instructions, such as robots.txt, noindex tag, robots meta tag, and X-Robots-Tag.
Robots.txt is a root directory file that restricts some pages or content elements from Google. Once Googlebot discovers your page, it looks at the robots.txt file. If the discovered page is restricted from crawling by robots.txt, Googlebot stops crawling and loading any content and scripts from that page. This page will not appear in search.
Robots.txt file can be generated in WebSite Auditor (Preferences > Robots.txt Settings).
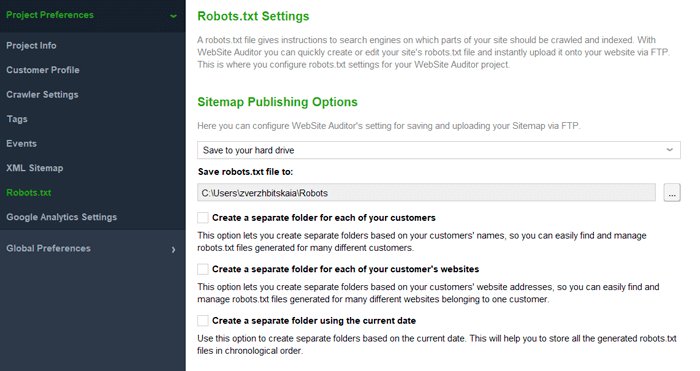
Noindex tag, robots meta tag, and X-Robots-Tag are the tags used to restrict crawlers from crawling and indexing a page. A noindex tag restricts the page from indexing by all types of crawlers. A robots meta tag is used to specify the way how a certain page should be crawled and indexed. This means that you can prevent some types of crawlers from visiting the page, and keep it open to others. An X-Robots-Tag can be used as an element of the HTTP header response that may restrict the page from indexing, or navigate crawlers’ behavior on the page. This tag lets you target separate types of crawling robots (if specified). If the robot type is not specified, the instructions will be valid for all types of crawlers.
Note: Robots.txt file doesn’t guarantee that the page is excluded from indexing. Googlebot treats this document rather as a recommendation than an order. This means Google can ignore robots.txt and index a page for search. If you want to make sure the page will not be indexed, use a noindex tag.
Are all pages available for crawling?
No. Some pages may be unavailable for crawling and indexing. Let’s have a closer look at these types of pages:
- Password-protected pages. Googlebot simulates the behavior of an anonymous user who doesn’t have any credentials to visit protected pages. So if a page is protected with a password, it will not be crawled, as Googlebot will be unable to reach it.
-
Pages excluded by indexing instructions. These are the pages from robots.txt, pages with a noindex tag, robots meta tag, and X-Robots-Tag.
-
Orphan pages. Orphan pages are the pages that are not linked to from any other page on the website. Googlebot is a spider-robot, which means it discovers new pages by following all the links it finds. If there are no links that point to a page, then the page will not be crawled, and will not appear in search.
Some of the pages are restricted from crawling and indexing on purpose. These are usually the pages that are not intended to appear in search: pages with personal data, policies, terms of use, test versions of pages, archive pages, internal search result pages, and so on.
But if you want to make your pages available for crawling and bring you traffic, make sure you don’t protect public pages with passwords, mind linking (internal and external), and carefully check indexing instructions.
To check the crawlability of your website’s pages in Google Search Console, go to Index > Coverage report. Pay attention to the issues marked Error (not indexed) and Valid with warning (indexed, though has issues).
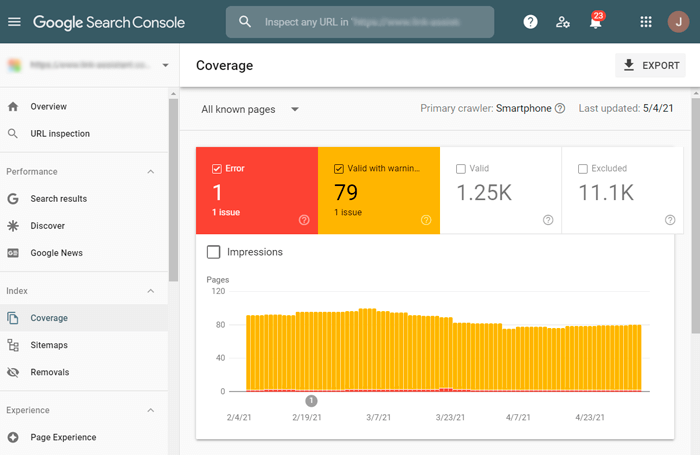
To get more details on crawling and indexing issues and learn how to fix them, read our comprehensive Google Search Console guide.
You can also run a more comprehensive indexing audit with WebSIte Auditor. The tool will not only show the issues with the pages available for indexing but show you the pages Google doesn’t see yet. Launch the software, and go to Site Structure > Site Audit section.
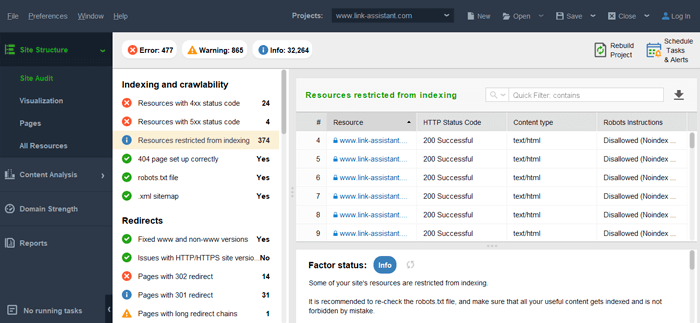
Note: If you don’t want Googlebot to find or update any pages (some old pages, pages you don’t need anymore), remove them from sitemap if you have one, set up 404 Not Found status, or mark them with a noindex tag.
When will my website appear in search?
It’s clear that your pages will not appear in search immediately after you make your website live. If your website is absolutely new, Googlebot will need some time to find it on the web. Keep in mind that this “some” may take up to 6 months in some cases.
If Google already knows your website, and you made some updates or added new pages, then the speed of website changes’ appearance on the web depends on the crawl budget.
Crawl budget is the amount of resources that Google spends on crawling your website. The more resources Googlebot needs to crawl your website, the slower it will appear in search.
Crawl budget allocation depends on the following factors:
- Website popularity. The more popular a website is, the more crawling points Google is willing to spend on its crawling.
-
Update rate. The more often you update your pages, the more crawling resources your website will get.
-
Number of pages. The more pages you have, the bigger your crawling budget will be.
-
Server capacity to handle crawling. Your hosting servers must be capable to respond to crawlers’ requests on time.
Please note that the crawl budget is not spent equally on each page, as some pages drain more resources (because of heavy JavaScript and CSS or because HTML is messy). So the crawl budget allocated may not be enough to crawl all of your pages as quickly as you may expect.
In addition to heavy code problems, some of the most common causes of poor crawling and irrational crawl budget expenses are duplicate content issues and badly structured URLs.
Duplicate content issues
Duplicate content is having several pages with mostly similar content. This can happen for many reasons, such as:
- Reaching the page in different ways: with or without www, through http or https;
-
Dynamic URLs — when many different URLs lead to the same page;
-
A/B testing of pages’ versions.
If not fixed, duplicate content issues result in Googlebot crawling the same page several times, as it would consider these are all different pages. Thus crawling resources are wasted in vain, and Googlebot may not manage to find other meaningful pages of your website. In addition, duplicate content lowers your pages’ positions in search, as Google may decide that your website’s overall quality is low.
The truth is that in most cases you cannot get rid of most of the things that may cause duplicate content. But you can prevent any duplicate content issues by setting up canonical URLs. A canonical tag signalizes which page should be considered “the main”, thus the rest of the URLs pointing to the same page will not be indexed, and your content will not duplicate. You can also restrict robots from visiting dynamic URLs with the help of the robots.txt file.
URL structure issues
User-friendly URLs are appreciated by both humans and machine algorithms. Googlebot is not an exception. Googlebot may be confused when trying to understand long and parameter-rich URLs. Thus more crawling resources are spent. To prevent this, make your URLs user-friendly.
Make sure your URLs are clear, follow a logical structure, have proper punctuation, and don’t include complicated parameters. In other words, your URLs should look like this:
http://example.com/vegetables/cucumbers/pickles
Note: Luckily, crawl budget optimization is not as complicated as it may seem. But the truth is that you only need to worry about this if you’re an owner of a large (1 million + pages) or a medium (10,000 + pages) website with frequently (daily or weekly) changing content. In the rest of the cases, you just need to properly optimize your website for search and fix indexing issues on time.
Conclusion
Google’s main crawler, Googlebot, operates under sophisticated algorithms, but you can still “navigate” its behavior to make it beneficial for your website. Besides, most of the crawling process optimization steps repeat those of standard SEO we are all familiar with.