- Trình thu thập thông tin là gì?
- Trình thu thập thông tin hoạt động như thế nào?
- Trình thu thập thông tin xem các trang như thế nào?
- Kết xuất thiết bị di động và máy tính để bàn
- Hiển thị HTML và JavaScript
- Điều gì ảnh hưởng đến hành vi của trình thu thập thông tin?
- Độ sâu nhấp chuột
- Sơ đồ trang web
- Hướng dẫn lập chỉ mục
- Tất cả các trang có sẵn để thu thập thông tin không?
- Khi nào trang web của tôi sẽ xuất hiện trong tìm kiếm?
- Các vấn đề về nội dung trùng lặp
- Các vấn đề về cấu trúc URL
- Phần kết luận
Đầu tiên, Google thu thập dữ liệu web để tìm các trang mới. Sau đó, Google lập chỉ mục các trang này để hiểu nội dung của chúng và xếp hạng chúng theo dữ liệu được truy xuất. Thu thập thông tin và lập chỉ mục là hai quá trình khác nhau, tuy nhiên, cả hai đều được thực hiện bởi trình thu thập thông tin.
Trong hướng dẫn mới của Vietnampedia, chúng tôi đã thu thập mọi thứ mà một chuyên gia SEO cần biết về trình thu thập thông tin. Để biết trình thu thập thông tin là gì, cách thức hoạt động và cách bạn có thể làm cho tương tác của nó với trang web của bạn thành công hơn.
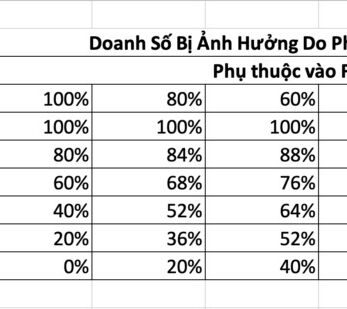
Trình thu thập thông tin là gì?
Crawler (cũng là searchbot, spider) là một phần mềm mà Google và các công cụ tìm kiếm khác sử dụng để quét Web. Nói một cách đơn giản, nó "thu thập dữ liệu" web từ trang này sang trang khác, tìm kiếm nội dung mới hoặc cập nhật mà Google chưa có trong cơ sở dữ liệu của mình.
Bất kỳ công cụ tìm kiếm nào cũng có bộ trình thu thập thông tin của riêng nó. Đối với Google, có hơn 15 loại trình thu thập thông tin khác nhau và trình thu thập thông tin chính của Google được gọi là Googlebot. Googlebot thực hiện cả thu thập thông tin và lập chỉ mục, đó là lý do tại sao chúng ta sẽ xem xét kỹ hơn cách hoạt động của nó.
Trình thu thập thông tin hoạt động như thế nào?
Không có sổ đăng ký trung tâm của các URL, chúng được cập nhật bất cứ khi nào một trang mới được tạo. Điều này có nghĩa là Google không tự động "cảnh báo" về chúng mà phải tìm chúng trên web. Googlebot liên tục lang thang trên Internet và tìm kiếm các trang mới, thêm chúng vào cơ sở dữ liệu của Google về các trang hiện có.
Khi Googlebot phát hiện ra một trang mới, nó sẽ hiển thị trang đó trong trình duyệt, tải tất cả HTML, mã của bên thứ ba, JavaScript và CSS. Thông tin này được lưu trữ trong cơ sở dữ liệu của công cụ tìm kiếm và sau đó được sử dụng để lập chỉ mục và xếp hạng trang. Nếu một trang đã được lập chỉ mục, nó sẽ được thêm vào Chỉ mục của Google - một cơ sở dữ liệu siêu khổng lồ nữa của Google.

Trình thu thập thông tin xem các trang như thế nào?
Trình thu thập thông tin hiển thị một trang trong phiên bản mới nhất của trình duyệt Chromium. Trong trường hợp hoàn hảo, trình thu thập thông tin “nhìn thấy” một trang theo cách bạn đã thiết kế và lắp ráp nó. Trong kịch bản thực tế, mọi thứ có thể trở nên phức tạp hơn.
Kết xuất thiết bị di động và máy tính để bàn
Googlebot có thể “nhìn thấy” trang của bạn bằng hai loại trình thu thập thông tin phụ: Googlebot Desktop và Googlebot Smartphone. Sự phân chia này là cần thiết để lập chỉ mục các trang cho cả SERP trên máy tính để bàn và thiết bị di động.
Vài năm trước, Google đã sử dụng trình thu thập thông tin trên máy tính để bàn để truy cập và hiển thị hầu hết các trang. Nhưng mọi thứ đã thay đổi với sự ra đời của khái niệm ưu tiên thiết bị di động. Google nghĩ rằng thế giới đã đủ thân thiện với thiết bị di động và bắt đầu sử dụng Googlebot Smartphone để thu thập thông tin, lập chỉ mục và xếp hạng phiên bản di động của các trang web cho cả SERP trên thiết bị di động và máy tính để bàn.
Tuy nhiên, việc triển khai lập chỉ mục ưu tiên thiết bị di động hóa ra khó hơn dự kiến. Internet là rất lớn và hầu hết các trang web dường như được tối ưu hóa kém cho các thiết bị di động. Điều này khiến Google sử dụng khái niệm ưu tiên thiết bị di động để thu thập thông tin và lập chỉ mục các trang web mới và những trang web cũ đã được tối ưu hóa hoàn toàn cho thiết bị di động. Nếu một trang web không thân thiện với thiết bị di động, nó sẽ được Googlebot Desktop thu thập dữ liệu và hiển thị trực tiếp.
Ngay cả khi trang web của bạn đã được chuyển đổi sang tính năng ưu tiên lập chỉ mục trên thiết bị di động, bạn vẫn sẽ có một số trang của mình được Googlebot Desktop thu thập thông tin, vì Google muốn kiểm tra trang web của bạn hoạt động như thế nào trên máy tính để bàn. Google không trực tiếp nói rằng họ sẽ lập chỉ mục phiên bản dành cho máy tính để bàn của bạn nếu nó khác nhiều so với phiên bản dành cho thiết bị di động. Tuy nhiên, thật hợp lý khi giả định điều này, vì mục tiêu chính của Google là cung cấp cho người dùng thông tin hữu ích nhất. Và Google hầu như không muốn mất thông tin này bằng cách mù quáng tuân theo khái niệm ưu tiên di động.
Lưu ý: Trong mọi trường hợp, trang web của bạn sẽ được truy cập bởi cả Googlebot Mobile và Googlebot Desktop. Vì vậy, điều quan trọng là phải quan tâm đến cả hai phiên bản trang web của bạn và nghĩ đến việc sử dụng bố cục đáp ứng nếu bạn chưa làm điều này.
Làm cách nào để biết liệu Google có thu thập dữ liệu và lập chỉ mục trang web của bạn với khái niệm ưu tiên thiết bị di động hay không? Bạn sẽ nhận được một thông báo đặc biệt trong Google Search Console.
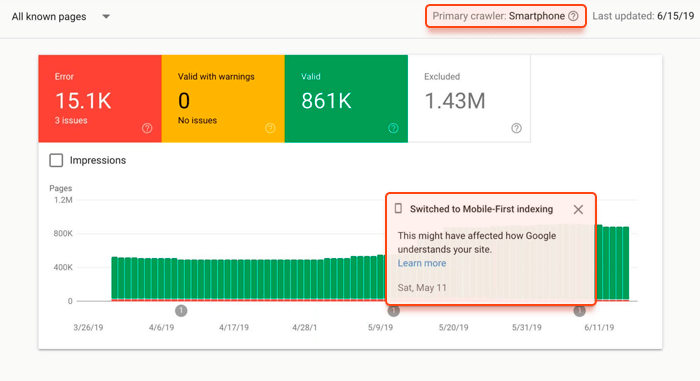
Hiển thị HTML và JavaScript
Googlebot có thể gặp một số rắc rối với việc xử lý và hiển thị mã cồng kềnh. Nếu mã trang của bạn lộn xộn, trình thu thập thông tin có thể không hiển thị đúng cách và coi trang của bạn trống.
Đối với kết xuất JavaScript, bạn nên nhớ rằng JavaScript là một ngôn ngữ phát triển nhanh chóng và Googlebot đôi khi có thể không hỗ trợ các phiên bản mới nhất. Đảm bảo rằng JS của bạn tương thích với Googlebot, nếu không trang của bạn có thể được hiển thị không chính xác.
Lưu ý đến thời gian tải JS của bạn. Nếu một tập lệnh cần hơn 5 giây để tải, Googlebot sẽ không hiển thị và lập chỉ mục nội dung được tạo bởi tập lệnh đó.
Lưu ý: Nếu trang web của bạn có đầy đủ các phần tử JS nặng và bạn không thể làm được nếu không có chúng, Google khuyên bạn nên kết xuất phía máy chủ. Điều này sẽ làm cho trang web của bạn tải nhanh hơn và ngăn chặn lỗi JavaScript.
Để xem tài nguyên nào trên trang của bạn gây ra sự cố hiển thị (và thực sự xem bạn có gặp vấn đề gì không), hãy đăng nhập vào tài khoản Google Search Console của bạn, đi tới Kiểm tra URL, nhập URL bạn muốn kiểm tra, nhấp vào nút Kiểm tra URL trực tiếp và nhấp vào Xem trang đã kiểm tra.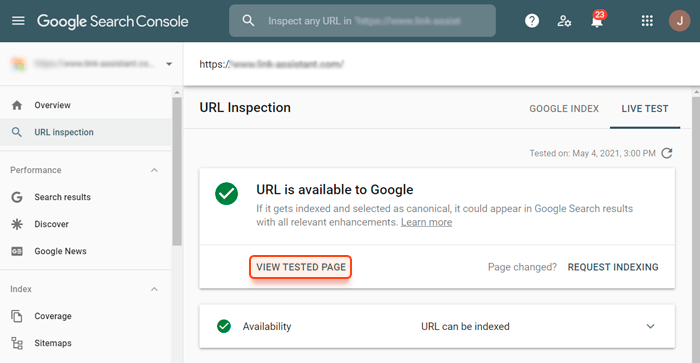
Sau đó, đi tới phần Thông tin khác và nhấp vào Tài nguyên trang và thư mục thông báo bảng điều khiển JavaScript để xem danh sách tài nguyên mà Googlebot không thể hiển thị.
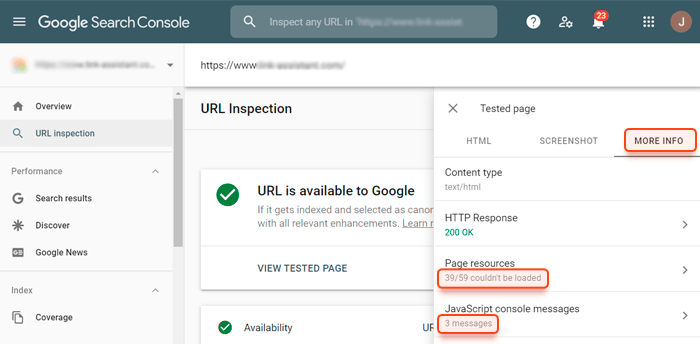
Giờ đây, bạn có thể hiển thị danh sách các vấn đề cho quản trị viên web và yêu cầu họ điều tra và sửa lỗi.
Điều gì ảnh hưởng đến hành vi của trình thu thập thông tin?
Hành vi của Googlebot không hỗn loạn - nó được xác định bởi các thuật toán phức tạp, giúp trình thu thập thông tin điều hướng trên web và đặt ra các quy tắc xử lý thông tin.
Tuy nhiên, hành vi của các thuật toán không phải là thứ mà bạn không thể làm gì cả và hy vọng điều tốt nhất. Hãy xem xét kỹ hơn những gì ảnh hưởng đến hành vi của trình thu thập thông tin và cách bạn có thể tối ưu hóa việc thu thập thông tin các trang của mình.
Liên kết nội bộ và liên kết ngược
Nếu Google đã biết trang web của bạn, Googlebot sẽ kiểm tra các trang chính của bạn để cập nhật theo thời gian. Đó là lý do tại sao điều quan trọng là phải đặt các liên kết đến các trang mới trên các trang có thẩm quyền của trang web của bạn. Lý tưởng nhất là trên trang chủ.
Bạn có thể làm phong phú thêm trang chủ của mình với một khối có các tin tức mới nhất hoặc các bài đăng trên blog, ngay cả khi bạn có các trang riêng biệt cho tin tức và một blog. Điều này sẽ cho phép Googlebot tìm thấy các trang mới của bạn nhanh hơn nhiều. Khuyến nghị này có vẻ khá rõ ràng, tuy nhiên, nhiều chủ sở hữu trang web vẫn tiếp tục bỏ qua nó, dẫn đến việc lập chỉ mục kém và vị trí thấp.
Về mặt thu thập thông tin, các liên kết ngược hoạt động giống nhau. Vì vậy, nếu bạn thêm một trang mới, đừng quên quảng cáo bên ngoài. Bạn có thể thử đăng bài với tư cách khách, khởi chạy chiến dịch quảng cáo hoặc thử bất kỳ phương tiện nào khác mà bạn muốn làm cho Googlebot thấy URL của trang mới của bạn.
Lưu ý: Các liên kết phải dofollow để cho phép Googlebot theo dõi chúng. Mặc dù Google gần đây đã tuyên bố rằng các liên kết nofollow cũng có thể được sử dụng làm gợi ý để thu thập thông tin và lập chỉ mục, chúng tôi vẫn khuyên bạn nên sử dụng dofollow. Chỉ để đảm bảo trình thu thập thông tin nhìn thấy trang.
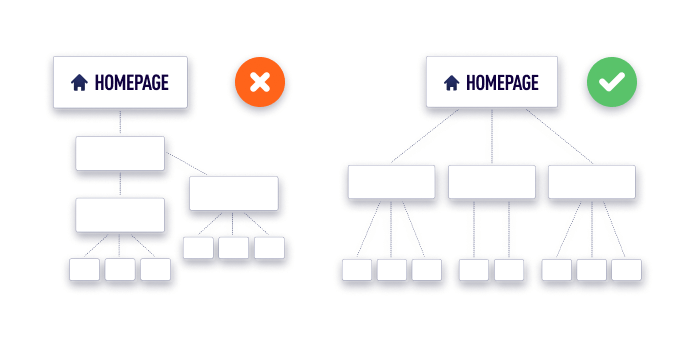
Độ sâu nhấp chuột
Độ sâu nhấp chuột cho biết trang cách trang chủ bao xa. Tốt nhất, bất kỳ trang nào của một trang web nên được truy cập trong vòng 3 cú nhấp chuột. Độ sâu nhấp chuột lớn hơn sẽ làm chậm quá trình thu thập dữ liệu và hầu như không mang lại lợi ích cho trải nghiệm người dùng.
Bạn có thể sử dụng WebSite Auditor để kiểm tra xem trang web của bạn có bất kỳ vấn đề nào liên quan đến độ sâu nhấp chuột hay không. Khởi chạy công cụ và đi tới Cấu trúc trang web> Trang, và chú ý đến cột Độ sâu nhấp chuột.
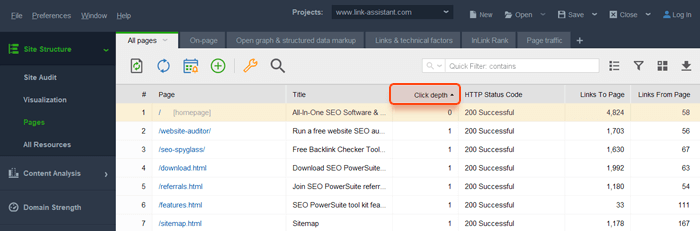
Nếu bạn thấy một số trang quan trọng nằm quá xa trang chủ, hãy xem xét lại việc sắp xếp cấu trúc trang web của bạn. Một cấu trúc tốt phải đơn giản và có thể mở rộng, vì vậy bạn có thể thêm bao nhiêu trang mới tùy ý mà không ảnh hưởng tiêu cực đến sự đơn giản.
Sơ đồ trang web
Sơ đồ trang web là một tài liệu chứa danh sách đầy đủ các trang mà bạn muốn có trong Google. Bạn có thể gửi sơ đồ trang web của mình cho Google thông qua Google Search Console (Chỉ mục> Sơ đồ trang web) để cho Googlebot biết những trang nào cần truy cập và thu thập thông tin. Sơ đồ trang web cũng cho Google biết nếu có bất kỳ cập nhật nào trên các trang của bạn.
Lưu ý: Sơ đồ trang web không đảm bảo rằng Googlebot sẽ sử dụng nó khi thu thập dữ liệu trang web của bạn. Trình thu thập thông tin có thể bỏ qua sơ đồ trang web của bạn và tiếp tục thu thập thông tin trang web theo cách mà nó quyết định. Tuy nhiên, không ai bị phạt vì có sơ đồ trang web và trong hầu hết các trường hợp, nó được chứng minh là hữu ích. Một số CMS thậm chí còn tự động tạo sơ đồ trang, cập nhật và gửi đến Google để giúp quá trình SEO của bạn nhanh hơn và dễ dàng hơn. Cân nhắc gửi sơ đồ trang nếu trang web của bạn mới hoặc lớn (có hơn 500 URL).
Bạn có thể tập hợp một sơ đồ trang bằng WebSite Auditor. Đi tới Tùy chọn> Cài đặt Sơ đồ trang web XML> Tạo Sơ đồ trang web và thiết lập các tùy chọn bạn cần. Đặt tên cho sơ đồ trang web của bạn (Tên tệp sơ đồ trang web) và tải xuống máy tính của bạn để gửi thêm cho Google hoặc xuất bản nó lên trang web của bạn (Xuất bản sơ đồ trang web).

Hướng dẫn lập chỉ mục
Khi thu thập dữ liệu và lập chỉ mục các trang của bạn, Google sẽ tuân theo một số hướng dẫn nhất định, chẳng hạn như robots.txt, thẻ noindex, thẻ meta rô bốt và X-Robots-Tag.
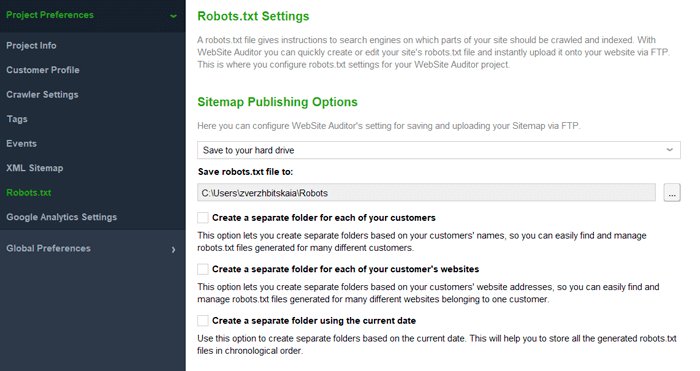
Robots.txt là một tệp thư mục gốc hạn chế một số trang hoặc phần tử nội dung từ Google. Khi Googlebot phát hiện ra trang của bạn, nó sẽ xem xét tệp robots.txt. Nếu trang được phát hiện bị hạn chế thu thập thông tin bởi robots.txt, Googlebot sẽ ngừng thu thập thông tin và tải bất kỳ nội dung cũng như tập lệnh nào từ trang đó. Trang này sẽ không xuất hiện trong tìm kiếm.
Tệp Robots.txt có thể được tạo trong WebSite Auditor (Tùy chọn> Cài đặt Robots.txt).
Thẻ ngăn lập chỉ mục, thẻ meta rô bốt và X-Robots-Tag là các thẻ được sử dụng để hạn chế trình thu thập thông tin thu thập thông tin và lập chỉ mục một trang. Thẻ ngăn lập chỉ mục hạn chế trang được lập chỉ mục bởi tất cả các loại trình thu thập thông tin. Thẻ meta rô bốt được sử dụng để chỉ định cách thu thập thông tin và lập chỉ mục một trang nhất định. Điều này có nghĩa là bạn có thể ngăn một số loại trình thu thập thông tin truy cập trang và giữ nó ở chế độ mở cho những người khác. Thẻ X-Robots-Tag có thể được sử dụng như một phần tử của phản hồi tiêu đề HTTP có thể hạn chế trang lập chỉ mục hoặc điều hướng hành vi của trình thu thập thông tin trên trang. Thẻ này cho phép bạn nhắm mục tiêu các loại rô bốt thu thập thông tin riêng biệt (nếu được chỉ định). Nếu loại rô bốt không được chỉ định, hướng dẫn sẽ có hiệu lực cho tất cả các loại trình thu thập thông tin.
Lưu ý: Tệp Robots.txt không đảm bảo rằng trang được loại trừ khỏi việc lập chỉ mục. Googlebot coi tài liệu này như một đề xuất hơn là một đơn đặt hàng. Điều này có nghĩa là Google có thể bỏ qua robots.txt và lập chỉ mục một trang để tìm kiếm. Nếu bạn muốn đảm bảo trang sẽ không được lập chỉ mục, hãy sử dụng thẻ ngăn lập chỉ mục.
Tất cả các trang có sẵn để thu thập thông tin không?
Không. Một số trang có thể không có sẵn để thu thập thông tin và lập chỉ mục. Chúng ta hãy xem xét kỹ hơn các loại trang này:
- Các trang được bảo vệ bằng mật khẩu. Googlebot mô phỏng hành vi của một người dùng ẩn danh không có bất kỳ thông tin xác thực nào để truy cập các trang được bảo vệ. Vì vậy, nếu một trang được bảo vệ bằng mật khẩu, nó sẽ không được thu thập thông tin vì Googlebot sẽ không thể truy cập được.
- Các trang bị loại trừ bởi hướng dẫn lập chỉ mục. Đây là các trang từ robots.txt, các trang có thẻ noindex, thẻ meta rô bốt và X-Robots-Tag.
- Trang mồ côi. Các trang mồ côi là các trang không được liên kết đến từ bất kỳ trang nào khác trên trang web. Googlebot là một robot nhện, có nghĩa là nó phát hiện ra các trang mới bằng cách theo dõi tất cả các liên kết mà nó tìm thấy. Nếu không có liên kết nào trỏ đến một trang, thì trang đó sẽ không được thu thập thông tin và sẽ không xuất hiện trong tìm kiếm.
Một số trang bị hạn chế thu thập thông tin và lập chỉ mục có chủ đích. Đây thường là những trang không nhằm mục đích xuất hiện trong tìm kiếm: trang có dữ liệu cá nhân, chính sách, điều khoản sử dụng, phiên bản thử nghiệm của trang, trang lưu trữ, trang kết quả tìm kiếm nội bộ, v.v.
Nhưng nếu bạn muốn cung cấp các trang của mình để thu thập thông tin và mang lại cho bạn lưu lượng truy cập, hãy đảm bảo rằng bạn không bảo vệ các trang công khai bằng mật khẩu, liên kết tâm trí (nội bộ và bên ngoài) và kiểm tra kỹ hướng dẫn lập chỉ mục.
Để kiểm tra khả năng thu thập dữ liệu của các trang trên trang web của bạn trong Google Search Console, hãy chuyển đến Chỉ mục> Báo cáo mức độ phù hợp. Chú ý đến các vấn đề được đánh dấu Lỗi (không được lập chỉ mục) và Hợp lệ với cảnh báo (được lập chỉ mục, mặc dù có vấn đề).
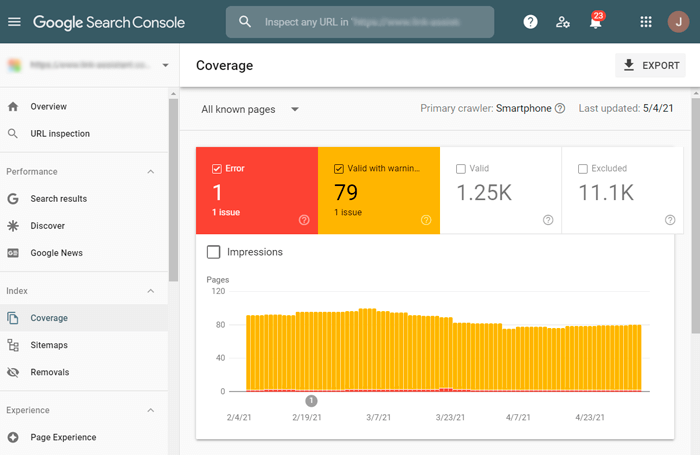
Để biết thêm chi tiết về các vấn đề thu thập dữ liệu và lập chỉ mục cũng như tìm hiểu cách khắc phục chúng, hãy đọc hướng dẫn toàn diện về Google Search Console của chúng tôi.
Bạn cũng có thể chạy kiểm tra lập chỉ mục toàn diện hơn với WebSIte Auditor. Công cụ sẽ không chỉ hiển thị các vấn đề với các trang có sẵn để lập chỉ mục mà còn hiển thị cho bạn những trang mà Google chưa thấy. Khởi chạy phần mềm và chuyển đến phần Cấu trúc trang web> Kiểm tra trang web.
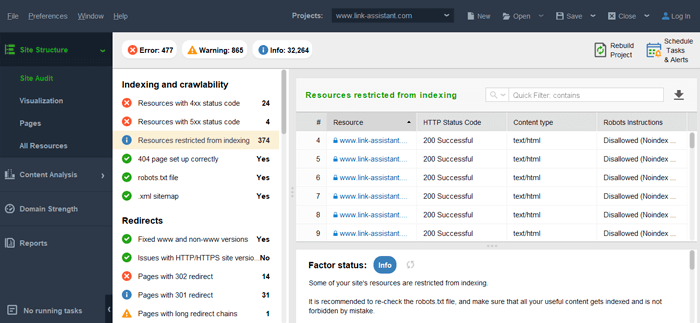
Lưu ý: Nếu bạn không muốn Googlebot tìm hoặc cập nhật bất kỳ trang nào (một số trang cũ, trang bạn không cần nữa), hãy xóa chúng khỏi sơ đồ trang web nếu bạn có, thiết lập trạng thái 404 Không tìm thấy hoặc đánh dấu chúng bằng thẻ noindex.
Khi nào trang web của tôi sẽ xuất hiện trong tìm kiếm?
Rõ ràng là các trang của bạn sẽ không xuất hiện trong tìm kiếm ngay sau khi bạn đưa trang web của mình vào hoạt động. Nếu trang web của bạn hoàn toàn mới, Googlebot sẽ cần một thời gian để tìm thấy nó trên web. Hãy nhớ rằng "một số" này có thể mất đến 6 tháng trong một số trường hợp.
Nếu Google đã biết trang web của bạn và bạn đã thực hiện một số cập nhật hoặc thêm trang mới, thì tốc độ xuất hiện của các thay đổi trang web trên web phụ thuộc vào ngân sách thu thập thông tin.
Ngân sách thu thập thông tin là lượng tài nguyên mà Google dành để thu thập thông tin trang web của bạn. Googlebot càng cần nhiều tài nguyên để thu thập dữ liệu trang web của bạn, thì trang web sẽ xuất hiện trong tìm kiếm càng chậm.
Thu thập thông tin phân bổ ngân sách phụ thuộc vào các yếu tố sau:
- Mức độ phổ biến của trang web. Một trang web càng phổ biến, thì càng có nhiều điểm thu thập dữ liệu mà Google sẵn sàng chi cho việc thu thập dữ liệu của nó.
- Tốc độ cập nhật. Bạn càng cập nhật các trang của mình thường xuyên, trang web của bạn sẽ nhận được càng nhiều tài nguyên thu thập dữ liệu.
- Số trang. Bạn càng có nhiều trang, ngân sách thu thập thông tin của bạn sẽ càng lớn.
- Dung lượng máy chủ để xử lý thu thập thông tin. Máy chủ lưu trữ của bạn phải có khả năng đáp ứng yêu cầu của trình thu thập thông tin đúng lúc.
Xin lưu ý rằng ngân sách thu thập thông tin không được chi đều trên mỗi trang, vì một số trang tiêu tốn nhiều tài nguyên hơn (vì JavaScript và CSS nặng hoặc vì HTML lộn xộn). Vì vậy, ngân sách thu thập thông tin được phân bổ có thể không đủ để thu thập thông tin tất cả các trang của bạn nhanh chóng như bạn có thể mong đợi.
Ngoài các vấn đề nghiêm trọng về mã, một số nguyên nhân phổ biến nhất của việc thu thập dữ liệu kém và chi phí ngân sách thu thập dữ liệu không hợp lý là các vấn đề về nội dung trùng lặp và URL có cấu trúc sai.
Các vấn đề về nội dung trùng lặp
Nội dung trùng lặp đang có một số trang có nội dung chủ yếu giống nhau. Điều này có thể xảy ra vì nhiều lý do, chẳng hạn như:
- Truy cập trang theo nhiều cách khác nhau: có hoặc không có www, thông qua http hoặc https;
- URL động - khi nhiều URL khác nhau dẫn đến cùng một trang;
- Thử nghiệm A/B phiên bản của các trang.
Nếu không được khắc phục, các vấn đề về nội dung trùng lặp dẫn đến việc Googlebot thu thập dữ liệu nhiều lần trên cùng một trang, vì nó sẽ coi đây là tất cả các trang khác nhau. Do đó, tài nguyên thu thập thông tin bị lãng phí một cách vô ích và Googlebot có thể không quản lý để tìm các trang có ý nghĩa khác trên trang web của bạn. Ngoài ra, nội dung trùng lặp làm giảm vị trí các trang của bạn trong tìm kiếm, vì Google có thể quyết định rằng chất lượng tổng thể của trang web của bạn thấp.
Sự thật là trong hầu hết các trường hợp, bạn không thể loại bỏ hầu hết những thứ có thể gây ra nội dung trùng lặp. Nhưng bạn có thể ngăn chặn mọi vấn đề về nội dung trùng lặp bằng cách thiết lập các URL chuẩn. Thẻ chuẩn báo hiệu trang nào nên được coi là "trang chính", do đó, phần còn lại của các URL trỏ đến cùng một trang sẽ không được lập chỉ mục và nội dung của bạn sẽ không bị trùng lặp. Bạn cũng có thể hạn chế rô bốt truy cập vào các URL động với sự trợ giúp của tệp robots.txt.
Các vấn đề về cấu trúc URL
URL thân thiện với người dùng được đánh giá cao bởi cả con người và thuật toán máy. Googlebot không phải là một ngoại lệ. Googlebot có thể bị nhầm lẫn khi cố gắng hiểu các URL dài và giàu thông số. Do đó, nhiều tài nguyên thu thập thông tin hơn được sử dụng. Để ngăn chặn điều này, hãy làm cho URL của bạn thân thiện với người dùng.
Đảm bảo URL của bạn rõ ràng, tuân theo cấu trúc hợp lý, có dấu câu thích hợp và không bao gồm các tham số phức tạp. Nói cách khác, URL của bạn sẽ giống như sau:
http://example.com/vegetables/cucumbers/pickles
Lưu ý: May mắn thay, việc tối ưu hóa ngân sách thu thập thông tin không phức tạp như bạn tưởng. Nhưng sự thật là bạn chỉ cần lo lắng về điều này nếu bạn là chủ sở hữu của một trang web lớn (1 triệu + trang) hoặc một trang web trung bình (10.000 + trang) với nội dung thay đổi thường xuyên (hàng ngày hoặc hàng tuần). Trong những trường hợp còn lại, bạn chỉ cần tối ưu hóa đúng cách trang web của mình để tìm kiếm và khắc phục các vấn đề lập chỉ mục đúng thời hạn.
Phần kết luận
Trình thu thập thông tin chính của Google, Googlebot, hoạt động theo các thuật toán phức tạp, nhưng bạn vẫn có thể “điều hướng” hành vi của nó để làm cho nó có lợi cho trang web của bạn. Bên cạnh đó, hầu hết các bước tối ưu hóa quy trình thu thập dữ liệu lặp lại các bước của chuẩn SEO mà chúng ta đã quen thuộc.